

1. 安装部署
1.1 windows系统部署教程
对于初学者而言,入门建议选择windows系统,版本需使用windows 10以上版本,现在国内windows系统整合包功能齐全,对于新手来说安装也比较方便。
(1)硬件要求
建议使用运行内存不少于16 GB内存的计算机,同时安装盘符预留100 GB以上的硬盘空间。
(2)显卡要求
因为跑图需要用到CUDA加速,而CUDA是NVIDIA推出的运算平台,所以只对NVIDIA显卡支持良好,虽然AMD等其它显卡也可以用于跑图,但是速度慢得多。
跑图建议使用8 GB以上显存显卡,最低配置RTX 3050,当然使用RTX3060、RTX4050、RTX4090等显卡效果更好,其它配置较低的显卡也可以跑图,只是速度会非常慢。
显卡算力越强,出图越快;显卡显存越高,所能设置的图片分辨率越高。
跑图和挖矿类似,GPU会 100% 运行,过度使用显卡有损坏的风险,特别是笔记本要注意散热,别长时间跑图。
(3)检查计算机配置
某些用户对计算机配置不了解,可以 点击下载鲁大师 进行检测。
(4) 检查N卡驱动
在安装webui之前,我们需要首先检查N卡驱动是否安装。
右击 此电脑 ,点击 管理,打开 设备管理器,点击 显卡适配器,双击 N卡,点击驱动程序可以看到 驱动程序版本,则 N卡驱动运行正常。一般来说,如 N卡驱动运行异常,显卡适配器 选项 N卡 那里有个黄色感叹号标志。
如未安装驱动,请前往英伟达官网下载对应显卡驱动,点击下载N卡驱动

(5) 检查CUDA安装情况
前面讲到,因为跑图需要用到CUDA加速,所以CUDA安装与否也需要进行检查。
检测是否安装CUDA,Win+R启动cmd,输入nvcc –V,如果已安装,则会显示CUDA版本信息,未成功安装则会报错。如果未安装CUDA,可以 点击下载 CUDA 。

(6) 软件安装部署
推荐直接使用整合包,B站秋叶制作的整合包非常好用,点击下载 Stable diffusion 整合包 。
① 安装 python 环境

点击下载 python,版本建议3.7以上,安装时必须勾选 Add Python to PATH。
安装完成后,Win+R启动cmd,输入 python --version,检查 python是否安装成功;输入 pip --version,检查pip管理包是否安装成功。
② 安装启动器运行依赖

双击 启动器运行依赖-dotnet-6.0.11.exe进行安装。
③ 运行启动器

将下载的整合包解压,打开 */stable diffusion/novelai-webui-aki-v3目录中的 A启动器.exe,等待验证本地程序完整性。

点击客户端右下角一键启动,稍等片刻会弹出用户协议,按要求填入我已阅读并同意用户协议,一定不要填错,填写后保存,关闭控制台,进入客户端重新点击一键启动,启动成功后会自动打开 http://127.0.0.1:7860 这个网址。

④ 测试跑图
选择stable diffusion模型,在文生图中输入提示词
panda点击生成,稍等片刻出图,stable diffusion即安装成功。

1.2 AutoDL云平台部署教程

对于部分用户,本地计算机配置较低无法运行webui,这时候我们可以考虑使用算力云租用GPU来运行Stable diffusion,虽然云平台是基于linux系统运行,相比windows系统比较复杂,但是只要跟着教程一步一步操作,这些也并不困难。
AutoDL是国内的平台,访问速度比较快,同时价格也比较合理,有按时/包日/包周/包月等比较灵活的付费方式,也便于我们选择。点击访问AutoDL
1.2.1 登录注册
AutoDL支持手机、微信登录,推荐使用微信扫码登录,比较方便,同时学生通过教育网邮箱认证后,还可以得到炼丹会员的折扣。
1.2.2 账号充值
登录控制台后,点击充值后选择其它金额,我们可以先充值5块钱试一下。

1.2.3 发票开具
有需要发票的还可以在控制台开具发票,点击费用找到发票管理即可。

1.2.4 安装部署
点击上方的算力市场即可租用算力,可以选择计费方式、地区、GPU型号。
对于新手而言,推荐使用包时的计费方式,地区选择西北地区,租用RTX 3080 Ti / 12 GB(¥1.14/时)或者RTX 4090 / 24 GB(¥2.61/时),数据盘默认不扩容。
点击社区镜像,选择AUTOMATIC1111/stable-diffusion-webui/NovelAI-Consolidation-Package-3.1:v15这个版本。

点击立即创建构建容器实列,构建容器实例第一次拉取镜像较慢,请耐心等候。
需要注意的是,构建的实例关机后如果15天未开机使用,AutoDL会清理实例。
当状态成为运行中,这个时候我们点击快捷工具下的JupyterLab。

打开JupyterLab后跳转一个新页面,左侧是文件目录,右侧是代码区域:

这里的安装比较简单,无需任何代码基础。
第一步:选中第一行代码
第二步:点击三角符号运行代码

第三步:运行完成后,第一行代码会显示“移动完成”。然后刷新浏览器,这一步务必刷新。

第四步:页面刷新完成后,右上角点击Python 3(ipykernel)。
 然后弹出选择内核的弹窗,选择
然后弹出选择内核的弹窗,选择xL_env,(如果没有刷新就没有这个选项)。

第五步:选中第二行代码,点击上面的三角符号运行代码,然后运行完成后如下图所示:

第六步:启动学术加速,因为AutoDL服务器在国内,而很多镜像资源服务器在国外,所以需要启动学术加速。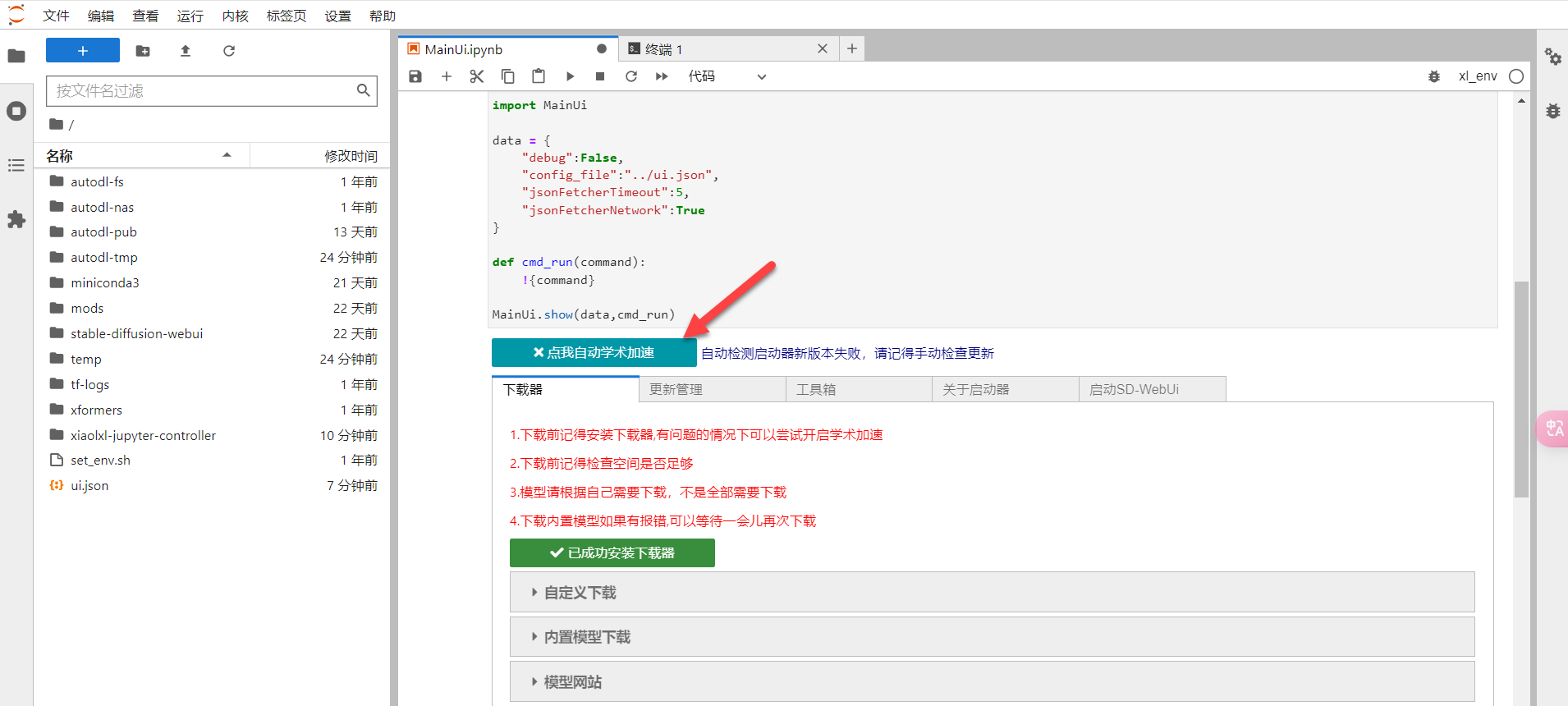
启动成功后如下图显示:

第七步:学术加速成功后,点击右侧启动SD-WebUI,往下拉点SD,启动按钮。

这时候系统会自动进行相关部署,稍等五分钟左右,部署成功后会显示:Running on local URL: http://127.0.0.1:6006

第八步:这时候我们返回控制台,点击自定义服务,然后点击访问。

这时候会自动跳转一个网页,让输入账号和密码。

第九步:这里返回JupyterLab页面,找到启动SD-WebUI选项,选择登录隐私设置,找到账号和密码。

输入账号和密码后,即可跳转到webui。

这里看到的界面与windows版本下秋叶启动器的界面略有不同,是因为这个启动器安装了不同的插件。
第十步:照例测试跑图,在文生图中输入提示词:
panda点击生成,稍等片刻出图,stable diffusion即安装成功。

1.2.5 其它建议
1.由于 AutoDL 新手大都选择按量计费也就是按小时计费,所以不用的时候,最好在控制台将容器实例关机。
2.由于算力云平台大都优先服务于包周/包月用户,有时候按量计费的用户,使用时开机却发现机器不处于空闲状态,这时候我们就可以考虑多租用几个容器实例,这样那个实例空闲我们选择那个实例即可。
3.由于实例15天未开机云平台会自动清空,所以重要资料即使做好备份,或者重要实例在时间范围内去开机使用下。
2. 文生图入门
2.1 选项功能介绍
先对面板相关功能进行初步了解,为了便于直观展示,这里将文生图相关功能进行标注。

点击放大图片
2.2 简单出图示例
大模型选择 majicMIX realistic_v7,你也可以选择其它模型,其它选项如上图所示,仅需输入正向提示词:
1girl,然后点击生成,稍等片刻即可以得到一张照片。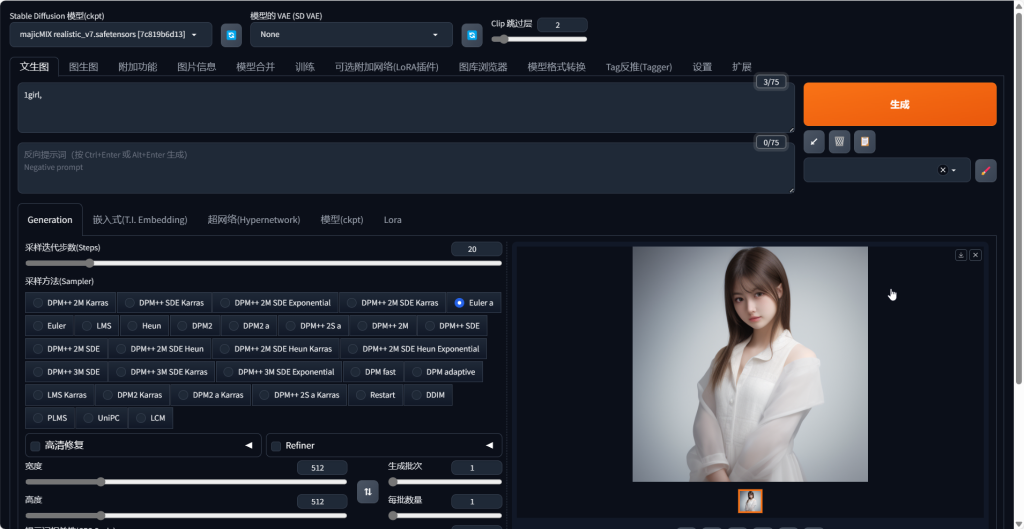
这是一个简单的出图示例,如果想得到更高质量的图片,则需要学会对其它选项进行设置。虽然选项粗看比较繁琐,但是庖丁解牛反复学习,逐一了解每个选项的用法,也会很容易事半功倍。
3. 模型用法
3.1 CheckPoint模型

Checkpoint模型,又称大模型或底模,决定了图片生成的风格。
通常文件大小在2G-7G之间,文件后缀为ckpt、safetensors。
存放路径为:*/stable-diffusion-webui/novelai-webui-aki-v3/models/Stable-diffusion

3.2 Lora模型
3.3 VAE模型[
3.3.1 VAE模型介绍

VAE,全名Variational autoenconder,中文叫变分自编码器。是模型算法组成部分之一,位于运作流程末端,作用是让出图颜色更鲜艳、细节更锐利;同时也能在一定程度上改善局部细节的生成质量,如手部、服装、脸部等,原理比较复杂,可以简单地把它理解为一种“滤镜”。
[success title=”示例1″]

左侧是没有使用VAE输出的图像,右侧是使用VAE输出的图像
[/success]
通常文件大小在300M-5G之间,文件后缀为pt、ckpt、safetensors。
存放路径为:
[mark]*/stable-diffusion-webui/novelai-webui-aki-v3/models/VAE[/mark]
3.3.2 VAE模型选择
VAE模型不能单独使用,需要配合大模型一起使用,但不是所有大模型都需要配合使用 VAE,因为部分大模型本身就自带 VAE,可以直接生成质量优异的图像。
① 阅读大模型使用说明
在 Civitai 等网站下载大模型时,一般模型作者都会使用说明里,说明是否会需要配合VAE使用。如下图的 Aniflatmix 大模型,在模型页面就建议搭配Orangemix / Anything V4.5 / NAI 这三种VAE 使用。

② 根据出图效果判断
要确定是否应该使用VAE,最简单的方法是观察生成的图像质量。如果图像的颜色看起来灰暗或泛白,与参考图像相比有显著的不同,这时就应该考虑启用VAE。
3.3.3 VAE模型下载
VAE模型的资源,就像其他AI绘图模型一样,主要分布在 Civitai 和 Huggingface 这两个网站。你可以在 Civitai模型 上筛选并查阅VAE资源,也可以直接在网上搜索特定的VAE名称来获取所需资源。
3.3.4 VAE模型推荐
① 官方VAE模型
Stability AI 官方发布了两个官方VAE模型:
这两个模型都能适配不同风格的大模型,并且能显著增强图像的色彩饱和度。根据使用体验,ema更锐利会明显地修改画面的细节、mse会更平滑对画面影响相对较小。
② 风格化VAE模型
某些VAE更适用于特定风格的大模型。在下载时,应仔细查看VAE开发者提供的使用指南。例如,ClearVAE、kl-f8-anime2、Anything等VAE,适合搭配动漫风大模型使用。
不同VAE下,图像生成效果会略有差异,大家可以根据实际情况对比选择:

[h2]3.4 Embedding模型[/h2]
3.4.1 Embedding模型介绍

Embedding(嵌入) 也叫 textual inversion (文本反转),它在深度学习领域通常指的是“嵌入式向量”,这些向量能够代表输入数据(如文本或图像)的关键特征。Embedding模型通常用来嵌入元素特征(比如人物特征/特定画风)、负面信息(用来减少图的崩坏几率),可以理解为Embedding的作用就是对提示词进行打包。
存放路径为:
[mark]*/stable-diffusion-webui/novelai-webui-aki-v3/embeddings[/mark]
通常文件大小在几十kb,文件后缀为pt、ckpt、safetensors。
3.4.2 Embeddings模型使用
①正向提示词
比如想生成一张《电锯人》中玛奇玛(Makima)这个角色的图像,选择 rabbit_v6 动漫风格大模型。
[success title=”输入提示词:”]
1girl, long hair, braided, white shirt, black tie, black pants
一个女孩,长发,扎着辫子,白衬衫,黑色领带,黑色裤

[/success]
在这种情况下,我们可以通过使用少量的玛奇玛图片来训练一个嵌入模型。这个模型能够在大模型创建玛奇玛图像时,把相应的特征关键字嵌入到大模型的词库中。这样一来,大模型就能“认识”玛奇玛的外观,从而自动生成准确的形象。
我们制作一个嵌入模型命名为 corneo_makima,同时存放在相应目录,更改提示词为:
1girl, long hair, braided, white shirt, black tie, black pants, corneo_makimazh如果我们把这个模型命名为“corneo_makima”,并在输入正向提示词时加上这个名称,就可以不需要我们提供详细的描述,自动地生成准确的玛奇玛形象。这样生成的图像就具有了玛奇玛图片的一些特征。

从上图可以看到,使用
同时由于训练数据较少,生成图像的精细度受限,个性化特征展现远不如lora模型那样稳定,因此在正向提示词的使用上并不普遍。
在图像生成过程中,为了防止产生质量不佳的图像,经常需要输入一些反向提示词:
[success title=”例如:”]
Low resolution, blur, facial features distortion, finger errors, watermarks
低分辨率、模糊、五官扭曲、手指错误、水印
[/success]
Embedding的优势在于,它能够将这些冗长的描述性提示词压缩成一个简洁的提示词,实现相同或更佳的效果,所以Embedding在反向提示词使用比较广泛。

EasyNegative 是一款目前广泛应用的反向提示词嵌入模型,它能有效地增强图像的细节,防止出现模糊、灰暗色调和面部畸形等问题,非常适合用于大型动漫风格的大模型。

badhandv4 是一个专为手部细节优化设计的反向提示词嵌入模型,它能在最小化对原始风格的干扰的同时,有效减少手部不完整、手指数目错误或多余手臂等问题,非常适合用于动漫风格大模型。
3.4.3 Embedding模型下载
Embedding模型的资源,就像其他AI绘图模型一样,主要分布在 Civitai 和 Huggingface 这两个网站。你可以在 Civitai模型 上筛选并查阅Embedding资源,也可以直接在网上搜索特定的Embedding名称来获取所需资源。
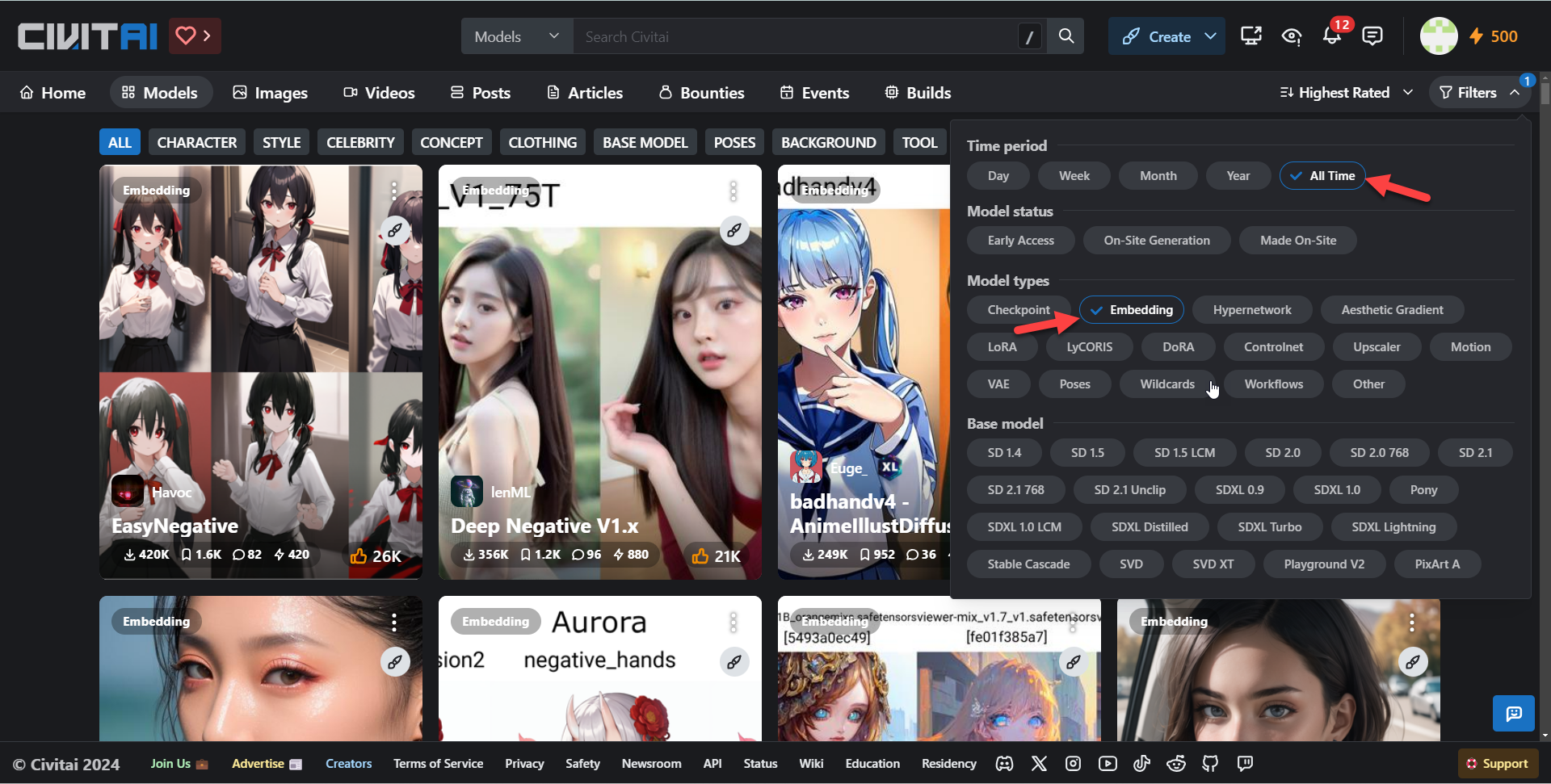
3.4.4 Embedding模型推荐
下面推荐6款 embedding 模型,大家可以根据自己的需要下载:
EasyNegative 是目前使用率极高的一款反向提示词 embedding 模型,可以有效提升画面的精细度,避免模糊、灰色调、面部扭曲等情况,适合动漫风大模型。
Deep Negative 可以提升图像的构图和色彩,减少扭曲的面部、错误的人体结构、颠倒的空间结构等情况的出现,无论是动漫风还是写实风的大模型都适用。
badhand 是一款专门针对手部进行优化的反向提示词 embedding 模型,能够在对原画风影响较小的前提下,减少手部残缺、手指数量不对、出现多余手臂的情况,适合动漫风大模型。
Fast Negative 也是一款非常强大的反向提示词 embedding 模型,它打包了常用的反向提示词,能在对原画风和细节影响较小的前提下提升画面精细度,动漫风和写实风的大模型都适用。
这两款 embedding 模型是专门为写实风大模型 DreamShaper 制作的,开发者是同一个人。BadDream 适合“dreamshaper 风格”的图像;UnrealisticDream 更适合写实逼真的图像,并且需要与 BadDream 或其他常规反向提示词一起使用。
[h2]3.5 模型后缀解析[/h2]
| 格式 | 描述 |
|---|---|
| .ckpt | Pytorch的标准模型保存格式,容易遭受Pickle反序列化攻击。 |
| .pt | Pytorch的标准模型保存格式,容易遭受Pickle反序列化攻击。 |
| .pth | Pytorch的标准模型保存格式,容易遭受Pickle反序列化攻击。 |
| .safetensors | safetensors格式可与Pytorch的模型相互格式转换,内容数据无区别。 |
| 其它 | webui 特殊模型保存方法:PNG、WEBP图片格式。 |
延伸阅读:什么是PyTorch?
3.5.1 safetensors和ckpt格式区别
- Safetensors格式所生成的内容与ckpt等格式完全一致。
- Safetensors格式拥有更高的安全性。
- Safetensors比ckpt格式加载速度更快。
- 该格式必须在2023年之后的Stable Diffusion内才可以使用,在此之间的SD版本内使用将无法识别。
- Safetensors格式由Huggingface推出,将会逐渐取代ckpt、pt、pth等格式,使用方法上与其它格式完全一致。
3.5.2 Pickle反序列化攻击
可以将字节流转换为一个对象,但是当我们程序接受任意输入时,如果用户的输入包含一些恶意的序列化数据,然后这些数据在服务器上被反序列化,服务器是在将用户的输入转换为一个对象,之后服务器就会被任意代码执行。
[h1]4.提示词撰写[/h1]
[h2]4.1 提示词语法[/h2]
文字提示词(prompt)分为正向提示词和反向提示词,提示词可以绘制出想象中的画面。
特别需要注意的是,提示词相关符号需使用半角符号。
[h3]4.1.1 分割符号[/h3]
在构建Prompt时,合理使用分割符号可以帮助提高生成图像的质量。常见的分割符号包括
[mark]逗号,[/mark]
[mark]圆括号()[/mark]
[mark]中括号[][/mark]
[mark]大括号{}[/mark]
[mark]尖括号<>[/mark]
。这些符号可以用于分隔不同的提示词,并赋予它们不同的权重和优先级。
①逗号
[mark]逗号, [/mark]
可用于分割词缀,且有权重排序功能,逗号前权重高,逗号后权重低,空格和换行等不影响词缀分隔。
[success title=”示例:”]
1girl, car
可能主体是女孩,衬托是汽车
car, 1girl
可能主体是汽车,衬托是女孩

[/success]
②小括号
[mark]小括号()[/mark]
每用一次代表权重提高1.1倍,支持多层嵌套方式,可以直接在括号里输入冒号接着写上权重的数值。
- (word) 提示词权重提高1.1倍
- ((word)) 提示词权重提高1.21倍(1.1*1.1)
- (word:1.5) 提示词权重提高1.5倍
- (word:0.25) 提示词权重减少4倍
③中括号
[mark]中括号[][/mark]
每用一次代表权重降低1.1倍,支持多层嵌套方式,不可以直接在括号里输入冒号接着写上权重的数值。
- [word] 提示词权重降低1.1倍
- [[word]]提示词权重降低1.21倍 ( 1.1 * 1.1)
④大括号
[mark]大括号{}[/mark]
每用一次代表权重降低1.1倍,支持多层嵌套方式,不可以直接在括号里输入冒号接着写上权重的数值。
- {word} 提示词权重提升1.05倍
- {{word}}提示词权重提升1.1025倍( 1.05 * 1.05)
[h3]4.1.2 权重控制[/h3]
①顺序原则
一般来说越靠前的词汇权重就会越高。
所以多数情况下的提示词格式是:质量词+媒介词+主体+主体描述+背景+背景描述+艺术风格
[success title=”示例:”]
masterpiece,bestquality,sketch,1girl,stand,black jacket,wall backgoround,full of poster杰作,最佳质量,速写,一个女孩,站立,黑色夹克,墙壁背景,充满海报

[/success]
②加权方式
可以通过分割符号
[mark]小括号()[/mark]
[mark]大括号{}[/mark]
进行加权,支持多层嵌套加权。
- (girl)代表girl提升1.1倍权重,((girl)代表提升1.1*1.1=1.21倍权重
- {girl}代表girl提升1.05倍权重,{{girl}}代表提升1.05*1.05=1.1025倍权重。
但是这样调整比较麻烦,一般用(girl: 1.5)这样的方式来控制权重。
③降权方式
可以通过分割符号
[mark]中括号[][/mark]
进行降权,支持多层嵌套加权。
- [girl]代表girl降低1.1倍权重,[[girl]]代表降低1.1*1.1=1.21倍权重。
但是这样调整比较麻烦,一般用(girl: 0.7)这样的方式来控制权重。‘’
[h3]4.1.3 分步绘制[/h3]
元素融合一般采用”|”或者“:”符号。
[h2]4.2 正向提示词[/h2]
正向提示词支持用自然语言进行描述,简而言之就是一句自然的话,从下图可以看到出图质量一般。
[success title=”示例”]
A girl wearing a sweater standing under cherry blossoms
一个女孩穿着毛衣在樱花下站着

[/success]
为了提升出图质量,通常将一句话分解成若干个关键词(tag),调整权重按序排列。
还是以上一句提示词为基础:
A girl wearing a sweater standing under cherry blossoms提取出以下关键词:
1girl, sweater, standing, cherry blossoms
将自然语言描述的句子中的关键词提取出来,用特定的方式进行排列,调整权重,使画面更接近自己想要的效果。
拆解法
公式法
[h2]4.3 反向提示词[/h2]
反向提示词(negative prompt)就是输入不想在画面中出现的内容,比如低质量图片、变形的手、多余的指头等。
反向提示词分两类,
- 一个是手动输入反向提示词语
- 一个是加载下载好的 Embedding
[h1]5.Clip 跳过层(Clip Skip)[/h1]
因为Stable Diffusion v1.5大部分模型都是将Clip Skip值设置为2训练出来的,所以在实际使用时通常把CLIP Skip值设置为2,出图质量更好更能反应提示词所表达的含义。
Clip 跳过层(Clip Skip)
[h2]5.1 Clip概念[/h2]
CLIP,全称是Contrastive Language-Image Pre-Training,中文的翻译是:通过语言与图像比对方式进行预训练,可以简称为图文匹配模型,即通过对语言和图像之间的一一对应关系进行比对训练,然后产生一个预训练的模型,能为日后有文本参与的生成过程所使用。
CLIP 本身也是一个神经网络,它将 Text Encoder 从文本中提取的语义特征和 Image Encoder 从图像中提取的图像特征进行匹配训练。这样的训练方式简单直接,且效果突出。研究人员发现在后续处理环节中,用来生成图像的 Diffusion 与表示的文本数据的 CLIP 可以非常好地协同工作,这也是为什么 Stable Diffusion 选择 CLIP 作为其图像生成方面的三大基础模型之一的原因。

标记化是计算机理解单词的方式,人类可以阅读单词,但计算机只能读取数字。这就是为什么文本提示词中的单词首先要被转换为数字,通常一个标记对应一个令牌。
在Stable Diffusion v1版本中,文本提示词(text prompt)由CLIP标记器(CLIP tokenizer)进行标记化。CLIP是一个由OpenAI开发的深度学习模型,用于为任何图像生成文本描述。
标记器只能对训练期间看到的单词进行分词。例如,CLIP 模型中有“dream”和“beach”,但没有“dreambeach”。Tokenizer 将“dreambeach”这个词分解为两个标记:“dream”和“beach”。因此,一个词并不总是意味着一个令牌!
另一个细则是空格字符也是令牌的一部分。在上述案例中,短语“dream beach”产生两个标记“dream”和“[space]beach”。这些令牌与“dreambeach”产生的令牌不同,后者是“dream”和“beach”。
Stable Diffusion 最多在提示中使用 75 个令牌,而不是75个字。
[h2]5.1 Clip跳过层概述[/h2]
为了在图像上反映文本提示词,CLIP标记器将文本标记化。
CLIP模型(Stable Diffusion 1.x 模型中存在的文本嵌入),具有由层组成的结构。
每一层都比上一层更具体。例如,如果第 1 层是人,则第 2 层可能是男性或女性,第 3 层可能是男人、男孩、父亲、爷爷等。请注意,这并不完全是 CLIP 模型的结构方式,而是为了举例说明。
例如,Stable Diffusion v1.5 模型的深度为 12 层。第 12 层是文本嵌入的最后一层,每一层都有一定大小的矩阵,并且每一层都有附加的矩阵。所以 4×4 第一层下面有 4 个 4×4……所以等等。所以文本空间在维度上他妈的很大。
CLIP模型由多个层组成,比如Stable Diffusion 1.5模型深度有12层。
这是一个在设置中的滑块,它控制 CLIP 网络对提示进行处理的提前停止时间。
更详细的解释:
CLIP 是一个非常先进的神经网络,它将您的提示文本转换为数值表示。神经网络非常适合使用这种数值表示,这就是为什么 SD 的开发者选择将 CLIP 作为稳定扩散方法中生成图像的三个模型之一的原因。由于 CLIP 是一个神经网络,这意味着它有很多层。您的提示以简单的方式被数字化,然后通过层进行馈送。在第一层之后,您会得到提示的数值表示,然后将其馈送到第二层,将该结果馈送到第三层,依此类推,直到达到最后一层,这是在稳定扩散中使用的 CLIP 的输出。这是滑块值为 1。但是您可以提前停止,使用倒数第二层的输出 – 这是滑块值为 2。您停止得越早,神经网络处理提示的层数就越少。
一些模型是通过这种调整进行训练的,因此在这些模型上设置此值有助于产生更好的结果。
注意:所有 SDXL 模型都是使用倒数第二(次级)层进行训练的。这就是为什么 Clip Skip 故意不会改变模型的结果,因为这只会使结果变得更糟。该选项仅由于早期的 SDv1 模型没有提供确定要使用的正确层的方式而提供。
[h1]6.采样迭代步数[/h1]
采样迭代步数是指在使用 Stable Diffusion 时,使用多少步将其绘制出来。在实际使用中,过少的步数会让图片降噪未完全完成;过多的步数会增加计算时间,同时很容易造成图片畸变。一般来说,采样步骤建议设置为20~30步。

从上图可以看出,步数设置为20步时,出图质量最高。高于20步时,女孩的形态反复变化,产生了一些畸变。
不同的模型最佳采样步骤会不同,这个需要大家反复进行测试,有些模型开发者也会在模型下载界面进行说明请注意阅读。
[h1]7.采样方法[/h1]
[h2]7.1 采样概念[/h2]

为了生成一张图片,Stable Diffusion首先在潜在空间中生成一个完全随机的图像,然后噪声预测器估计图像的噪声,预测的噪声被从图像中减去,这个过程重复多次,最后得到一张干净图像,这种去噪过程称为采样。在每个步骤都会生成一个新的采样图像,采样中使用的方法称为采样器或采样方法。
下面是一个采样示例,采样器逐渐产生越来越干净的图像。

[h2]7.2 噪声计划[/h2]
每次降噪都会对图像进行一次修改,通常降噪强度是前面几步较强,越到后面降噪强度越弱。这种针对每一步降噪强度的调控被称为噪声计划(Noise schedule)。目前webui中有default(默认)、Karras、Exponential三种噪声计划。
以下是default(默认)噪声计划,采样迭代步数为15步和30步的对比:
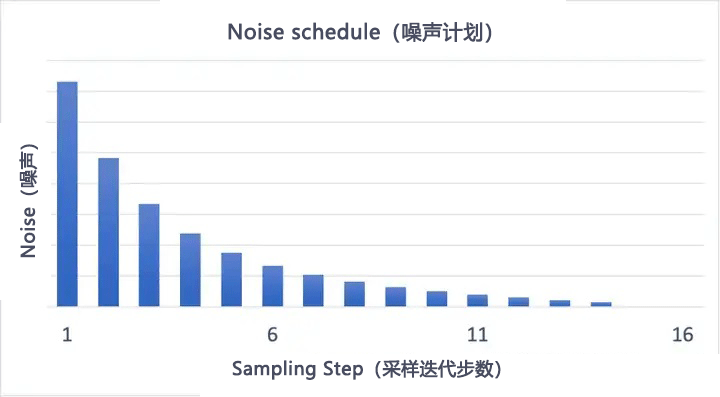 |
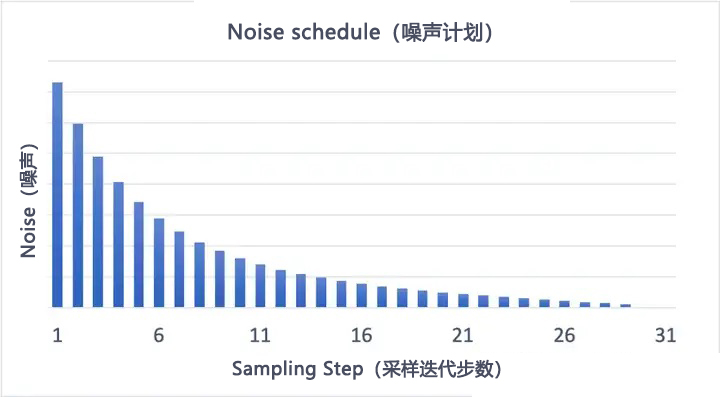 |
| 15步 | 30步 |
增加采样步数,可以减少每步之间的降噪幅度,这样可以避免截断误差。
不同的采样器在每一步的降噪强度可能各不相同,这使得采样器能够灵活地适应不同的应用场景和需求。
含有Karras词缀的采样器均使用了karras噪声计划,karras与默认(default)噪声计划对比如下图所示:

karras噪声计划在初始采样步骤中的噪声较多,而在结尾采样步骤中的噪声较少,实验表明这样有助于提高生成图片的质量。
[h2]7.3 采样收敛概念[/h2]
收敛是一个经济学、数学名词,是研究函数的一个重要工具,是指会聚于一点,向某一值靠近。
采样收敛是在扩散算法经过一定的采样迭代步数后,图像是否趋于稳定。换句话说,收敛是在连续迭代过程中图像前后变化幅度较小,不收敛是指在连续迭代过程中图像前后变化幅度较大。
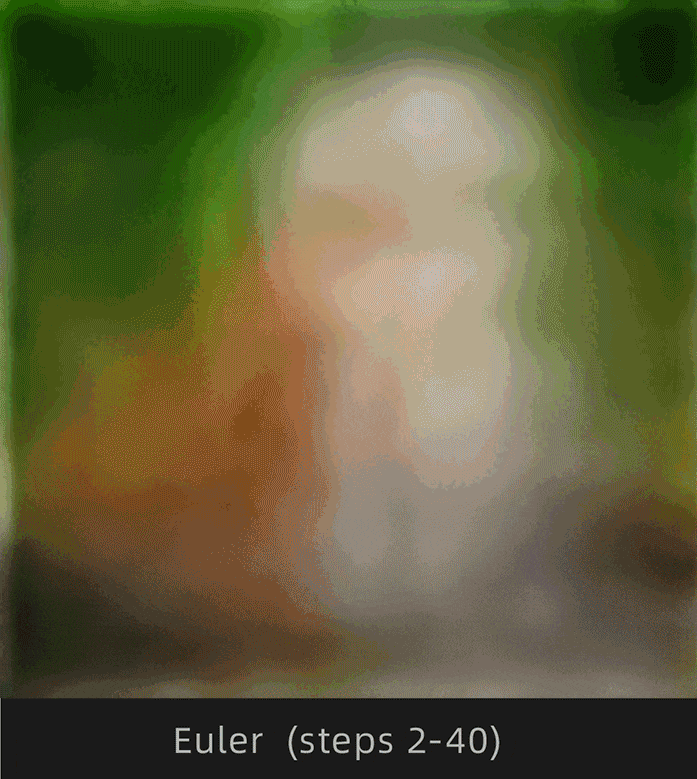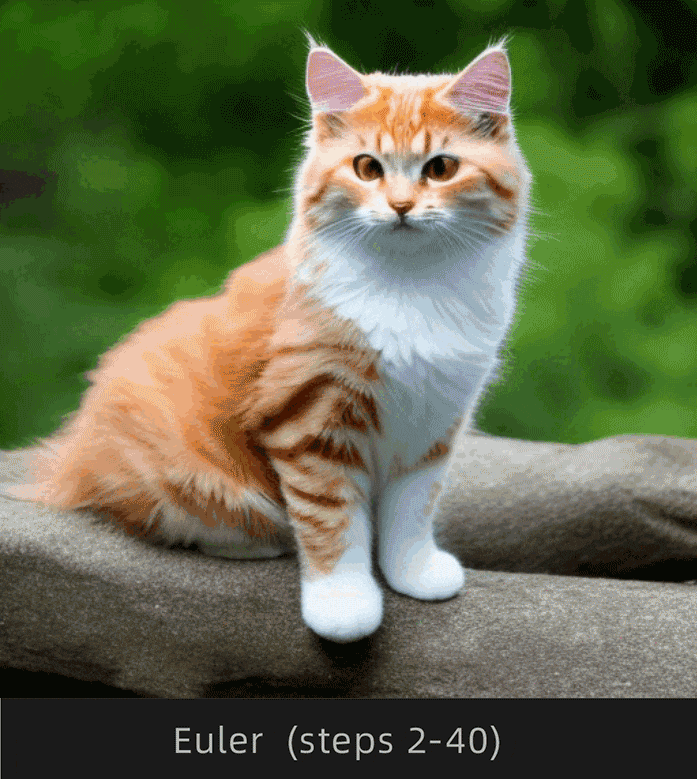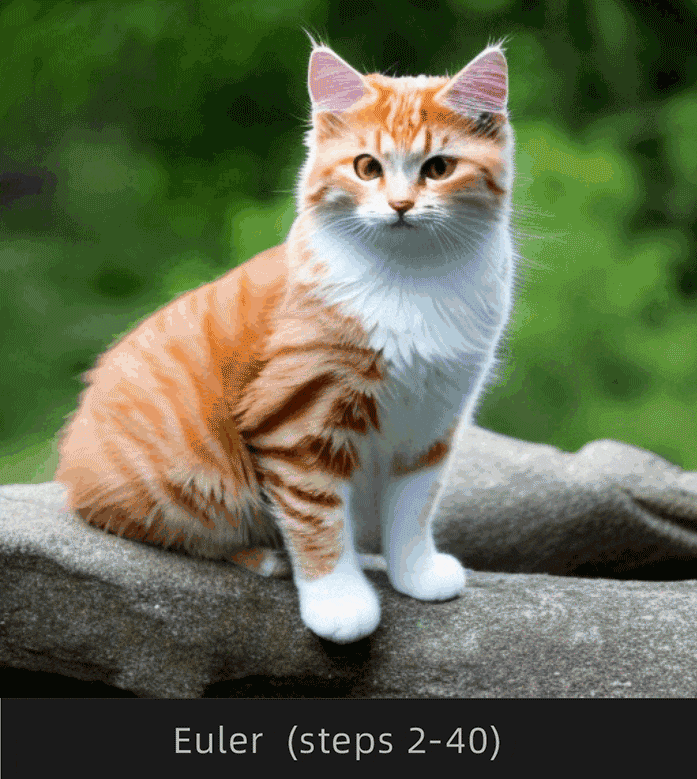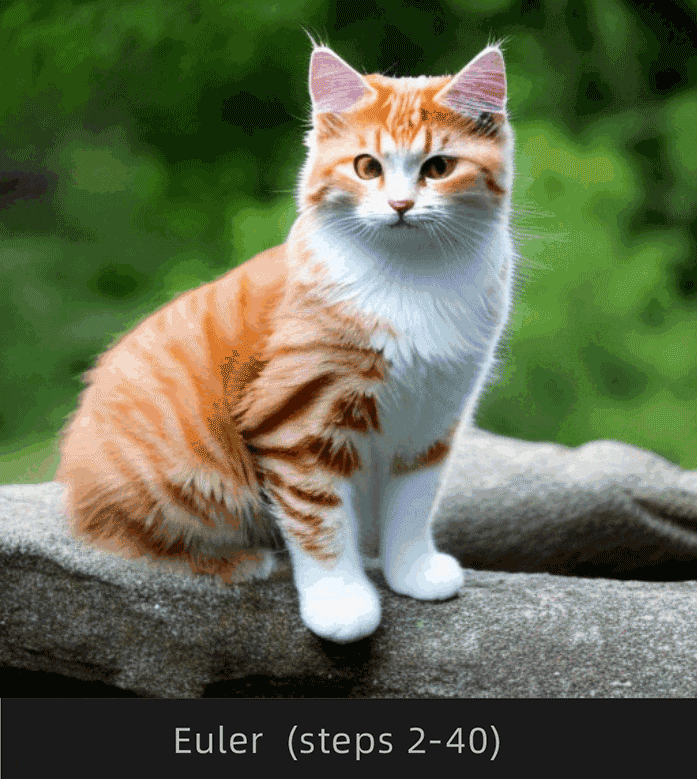 |
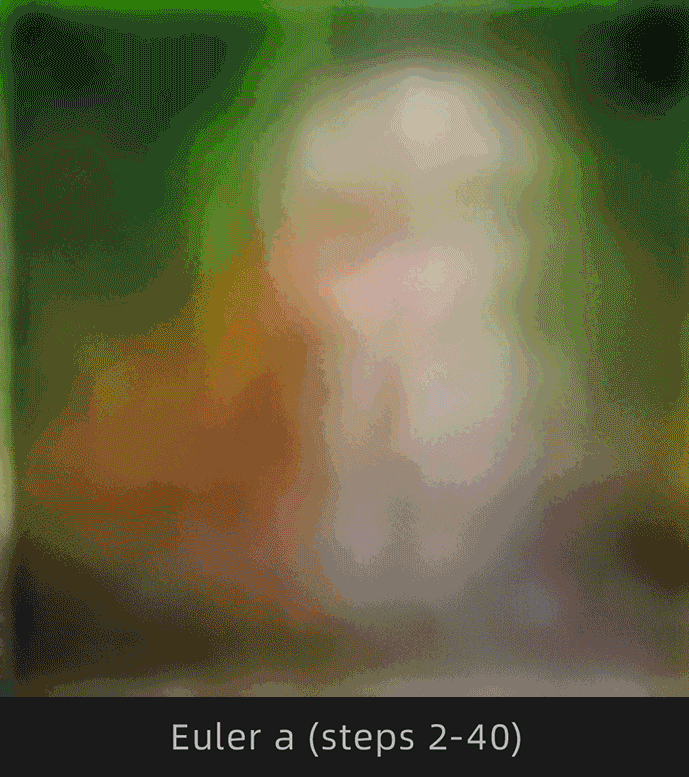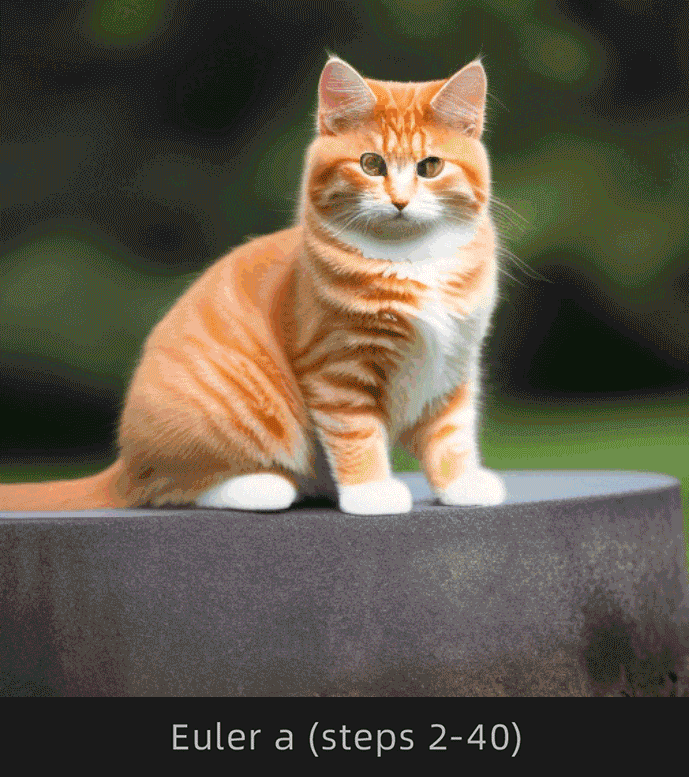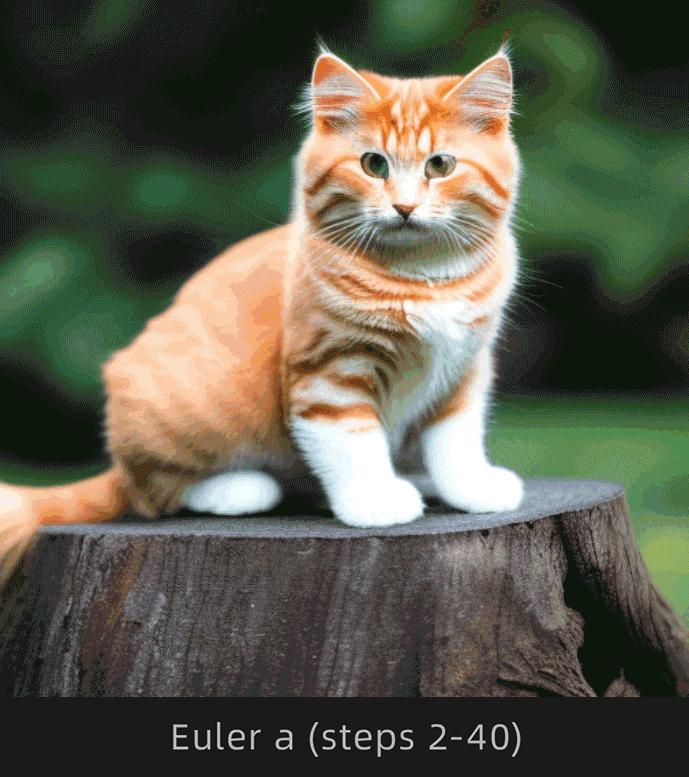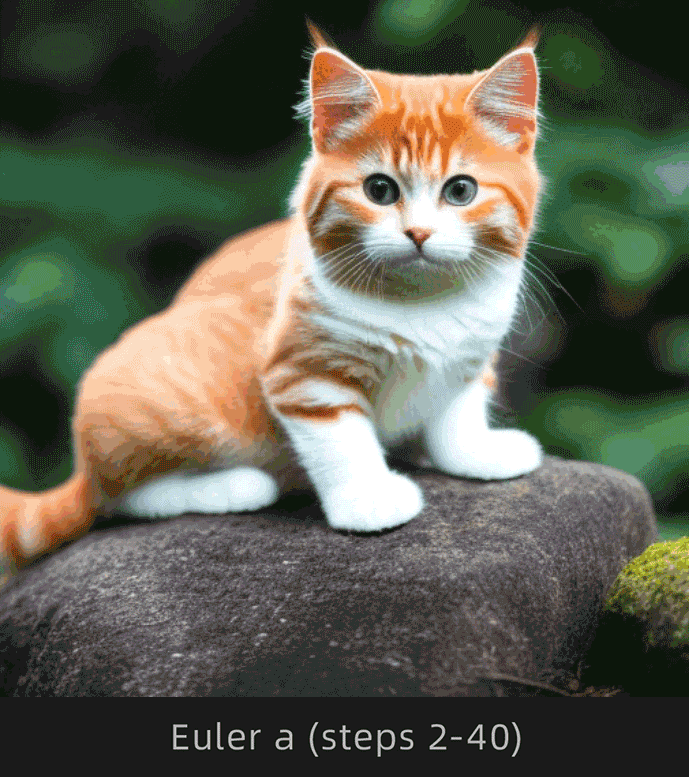 |
| 收敛,图像前后变化幅度较小 | 不收敛,图像前后变化幅度较大 |
注意观察Euler和Euler a采样器下猫背部的变化情况,Euler明显变化幅度较小,Euler a明显变化幅度较大。
为了便于理解,选择Euler和Euler a采样器,采样迭代步数选择1-30步进行对比:

这里挑选出以下步数对比更直观:

很明显Euler收敛,Euler a不收敛。
[h2]7.4 采样器词缀含义[/h2]

在 Stable Diffusion webui 中,已经整合了多种采样器,如 Euler a、DPM2、DDIM 和 Restart 等。随着算法的进步和新算法的涌现,预计将会不断增加更多的采样器,这些采样器各有特点,对图像生成的效果和速度影响不同。在选择采样器时,我们应该深入了解它们的算法特性。
[h3]7.4.1 “a”含义[/h3]
所有名字中包含独立字母a的采样器都是原始采样器(Ancestral sampling)。原始采样器在每一步采样时都向图像引入新的随机噪声,这导致图像内容不断变化,难以达到稳定状态,专业术语称之为难以收敛。
[h3]7.4.2 “2S/2M/3M”含义[/h3]
例如DPM++2s a、DPM++ 2M SDE、DPM++3M SDE等采样器带有这些数字标识,这里介绍下它们的含义。
数字的含义:
2代表是二阶采样器,3代表是三阶采样器。不带这些数字是一阶采样器,比如Euler、DDIM采样器。
采样器阶数越高,采样结果越准确,但是阶数越高,计算复杂度也更高,对算力要求越高。
在数学中,”阶”通常表示对某个变量的导数或微分。一阶通常涉及变量的第一导数或微分,而二阶涉及第二导数或微分。在优化和采样的上下文中,采用二阶方法意味着我们考虑了样本点及其变化情况。这有助于更准确地估计函数的形状和行为,进而更好地进行采样。
字母的含义:
S代表singlestep,即每次迭代只进行一步。这使得采样速度更快,但可能需要更多的步骤才能达到所需的图像质量。这种方法更适用于需要快速反馈或实时渲染的应用,因为它可以快速生成图像,尽管可能需要更多的迭代来达到理想效果。
M代表multistep,即每次迭代会执行多步。由于每次迭代需要进行多次更新,采样速度较慢,但通常只需要较少的采样步数就能达到所需的图像质量。这种方法更适合那些对图像质量要求较高的应用,或者愿意花费稍长时间以获得更好结果的应用。
[h3]7.4.3 “SDE”含义[/h3]
SDE(Stochastic Differential Equation)是随机微分方程的简称。简而言之,这类微分方程的使用使得噪声的建模方式更为复杂和精确,它能够利用之前步骤中的信息。原则上,这种方法能够生成更高质量的图像,但是处理速度较慢。由于采用了随机方法,SDE采样方法永远不会达到收敛状态。因此,增加处理步骤的数量并不会提高图像质量,而是会产生更多样化的结果,这一点类似于原始采样器。
[h3]7.4.4 “Karras ”含义[/h3]
含有Karras(或简写为K)字样的采样方法,均使用了Karras 噪声计划。Karras一词的由来,是指由 Nvidia 工程师 Tero Karras 所领导的一系列工作,这项工作为某些采样器带来重要改进,有效提高了输出质量和采样过程中计算效率。karras噪声计划在初始采样步骤中的噪声较多,而在结尾采样步骤中的噪声较少,可提高出图质量。
[h3]7.4.5 “Exponential”含义[/h3]
含有Exponential字样的采样方法,均使用了Exponential噪声计划。Exponential意思是指数映射优化,使用Exponential采样方法的画面更柔和、背景更干净但细节相对减少。
[h2]7.5 各采样器概述[/h2]
Euler
Euler欧拉采样方法,是最简单直接的采样方法。这种采样方法基于ODE(普通微分方程),其特点是在每一步处理中都会以固定的比例逐渐减少噪声。尽管因为其简单性而在精确度上有所欠缺,但是Euler因处理速度较快而被广泛应用。
Heun
Heun可以看作Euler采样方法的改进版。与Euler仅采用线性近似不同,Heun在每个处理步骤中执行两项任务,因此被称为二阶采样器。它先用线性近似做出预测,然后通过非线性近似来进行校正。这种方法在提高精确度的同时,也确保了更高的图像质量。然而,这种精确度的提升也有一个小代价,处理时间大约是Euler方法的两倍。
DDIM
DDIM(Denoising Diffusion Implicit Models,去噪扩散隐含模型)是Stable diffusion v1版本提供的采样器,它通常被认为已经过时,不再被广泛使用。
PLMS
PLMS(Pseudo Linear Multi-Step method,伪线性多步法)也是Stable diffusion v1版本提供的采样器,它也通常被认为已经过时,不再被广泛使用。
LMS
LMS(Linear Multi-Step method,线性多步骤方法)可以视为PLMS的一个变种,区别在于 LMS 使用的是数值方法,而非 PLMS 中的概率方法(从 PLMS 中去掉概率因素“P”就得到了 LMS)。与Euler和Heun不同的是,LMS 方法会利用前几个步骤中的信息来在每一步减少噪声。这样的处理方式虽然提高了图像的精度,但相应地也增加了计算需求,所以步骤较少的情况下容易出现色块。
DPM
DDPM(Denoising Diffusion Probabilistic Model,去噪扩散概率模型)是Stable diffusion最早期的采样器之一,它采用了明确的概率模型来消除图像中的噪声,现在webui中不提供此采样方法。DPM(Diffusion Probabilistic Model,扩散概率模型)是一种概率模型,它在DDPM的基础上进行了一系列改进,因此得名。
DPM2
DPM2 可以被视为DPM的升级版,相当于2代版本,它在原有模型的基础上做了改良和优化。
DPM++
DPM++是基于DPM的改进版本,DPM++ 采用了混合方法,它结合了确定性和概率性方法,进行采样以及处理后续噪声。
DPM fast
DPM fast是DPM的快速算法,效果较差基本不使用。
DPM adaptive
DPM adaptive是一种自适应的采样器,可能根据生成过程中的反馈信息动态调整参数和策略,以优化生成结果。
UniPC
UniPC (Unified Predictor-Corrector,统一预测-校正器)采样器是一种基于单个预测器的采样器,可能具有较低的计算成本和较快的生成速度,但可能会牺牲一些图像质量。
Restart
Restart采样器可能使用了一种特殊的重新启动机制,用于提高生成过程的稳定性和收敛性。
[h2]7.6 采样方法推荐[/h2]
前面我们对采样概念进行了一些了解,这里做一个思维导图便于大家进行理解。
推荐使用Euler、Euler a、DPM++ 2M Karras、DPM++ SDE Karras、DPM++ 2M SDE Karras、DPM++ 2M SDE Exponential、DPM++ 3M SDE Karras、DPM++ 3M SDE Exponentia采样器,下图进行了标红。

[h1]7.脚本用法[/h1]
webui中的脚本功能十分强大,内置的脚本提供了批量生成图片等功能,便于用户对比不同参数。
[h2]7.1 提示词矩阵[/h2]
生成图像时,通常需要反复调整提示词,来测试出图效果。然而,高频次修改提示词来生成图像比较繁琐,而且无法直观的对比图像。为了解决这个问题,可以使用提示词矩阵。提示词矩阵(Prompt matrix),可以在脚本中找到相关选项: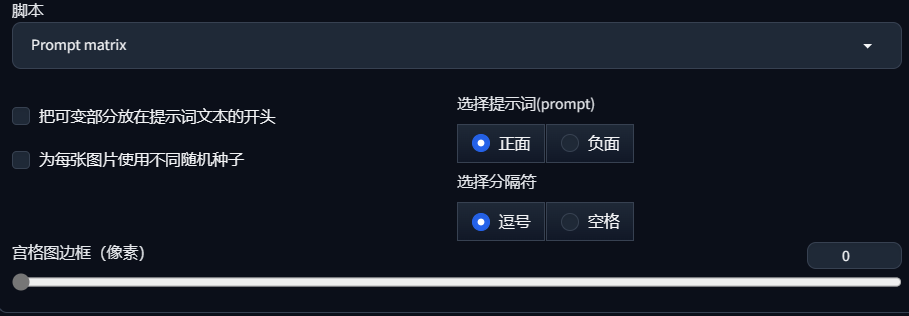
使用提示词矩阵,需要使用竖线符号
[mark]|[/mark]
将多个提示词分隔开。
[success title=”示例1:”]
[error title=”输入正向提示词:”]
1 cute girl, best quality|pink hair|black shirt|black glasses
一个可爱女生,最佳质量|粉色头发|黑色衬衫|黑色眼镜
[/error]
这里[mark]1 cute girl, best quality[/mark]不是变量,而[mark]|[/mark]后的[mark]pink hair、black shirt、black glasses[/mark]均是变量。脚本将变量排列组合后,形成8组提示词:
1 cute girl, best quality
1 cute girl, best quality, pink hair
1 cute girl, best quality, black shirt
1 cute girl, best quality, black glasses
1 cute girl, best quality, pink hair, black shirt
1 cute girl, best quality, pink hair, black glasses
1 cute girl, best quality, black shirt, black glasses
1 cute girl, best quality, pink hair, black shirt, black glasses
通过以上组合可以看出,除[mark]1 cute girl, best quality[/mark]之外,[mark]|[/mark]后面的提示词会相互组合进行出图。
[alert title=”特别提示:“]变量[mark]pink hair、black shirt、black glasses[/mark]也是有顺序的,所以排列组合后:
会存在 1 cute girl, best quality, pink hair, black shirt
不会存在
1 cute girl, best quality, black shirt, pink hair[/alert]
从下方的出图可以看到,通过提示词的不断组合,一共获得8张图片:
[/success]
[success title=”示例2:”]
下面我们尝试修改正向提示词,把 black glasses(黑色眼镜)修改为 twin braids(双辫子),来测试发型效果。
[error title=”修改后正向提示词为:”]
1 cute girl, best quality|pink hair|black shirt|twin braids一个可爱女生,最佳质量|粉色头发|黑色衬衫|双辫子
[/error]
脚本重新排列组合提示词后,形成8组提示词:
1 cute girl, best quality
1 cute girl, best quality, pink hair
1 cute girl, best quality, black shirt
1 cute girl, best quality, twin braids
1 cute girl, best quality, pink hair, black shirt
1 cute girl, best quality, pink hair, twin braids
1 cute girl, best quality, black shirt, twin braids
1 cute girl, best quality, pink hair, black shirt, twin braids
这里可以明显看到,第二排图片女孩由黑色眼镜变为了双辫子。

[/success]
需要注意的是,设置的组合提示词越多,组合情况越多,最终所需要出的图片也会越多,花费的时间也会越长,所以适当添加提示词即可。
7.1.1 把可变部分放在提示词文本的开头
把可变部分放在提示词文本的开头,就是把变量放在提示词的前面。
[success title=”示例3:”]
[error title=”勾选“把可变部分放在提示词文本的开头”,正向提示词输入:”]
1 cute girl, best quality|pink hair|black shirt|twin braids
一个可爱女生,最佳质量|粉色头发|黑色衬衫|双辫子
[/error]
这里[mark]1 cute girl, best quality[/mark]不是变量,而[mark]|[/mark]后的[mark]pink hair、black shirt、twin braids[/mark]均是变量。由于可变部分(变量)放在提示词文本的开头,脚本将变量排列组合后,形成8组提示词:
1 cute girl, best quality
pink hair, 1 cute girl, best quality
black shirt, 1 cute girl, best quality
twin braids, 1 cute girl, best quality
pink hair, black shirt, 1 cute girl, best quality
pink hair, twin braids, 1 cute girl, best quality
black shirt, twin braids, 1 cute girl, best quality
pink hair, black shirt, twin braids, 1 cute girl, best quality

[/success]
由于提示词的顺序原则,越靠前的提示词权重越高,所以勾选“把可变部分放在提示词文本的开头”对比不勾选“把可变部分放在提示词文本的开头”的出图,因为
[mark]pink hair、black shirt、twin braids[/mark]
这些变量权重更高,在出图中也相应元素体现得更加明显。
7.1.2 为每张图片使用不同随机种子
勾选这个选项,每次生成都会生成不一样的图片,这样生成的图片就没有对比性了,所以不建议不勾选。
7.1.3 选择提示词
脚本提示词作用域是在正向提示词区域还是反向提示词区域。
7.1.4 选择分割符
相互排列生成提示词的时候,是以逗号分割还是以空格进行分割,就是”|”替换成逗号还是空格,一般默认为逗号即可 。
7.1.5 宫格图边框
就是让生成的图片有边框,更容易区分照片。 [h2]7.2 从文本框或文件载入提示词[/h2]
[h2]7.2 从文本框或文件载入提示词[/h2]

从文本框或文件载入提示词(Prompts from file or textbox),可以一次性输入多组提示词,进行任务批处理,按顺序逐一生成图片。输入的方式可以是文本框,也可以是文件(txt格式)。
7.2.1 选项作用
- 每行输入都换一个随机种子:每条脚本提示词都使用不同的随机种子。
- 每行输入都使用同一个随机种子:每条脚本提示词都使用相同的随机种子。
- Insert prompts at the(插入提示词的位置):如果 Prompt(正向提示词)框中有内容,会与脚本提示词进行合并。”start” 表示将脚本提示词插入 Prompt 的前面;”end” 表示脚本提示词插入 Prompt 的后面。
- 提示词输入列表:输入脚本提示词的地方,每条脚本提示词使用换行符分割。
- 上传提示词输入文件:如果提示词脚本过多,可以将脚本提示词放到 txt 格式的文件,上传导入。
7.2.2 用法示例
简单示例:
在提示词列表中,输入以下四条提示词:a girl(一个女孩)、a boy(一个男孩)、a panda(一个熊猫)、a apple(一个苹果)。
a girl
a boy
a panda
a apple这样会按顺序生成四张照片,分别为一个女孩、一个男孩、一个熊猫、一个苹果:

进阶示例:
在提示词列表中,输入以下提示词
--prompt "city"
--prompt "snow mountain"
--prompt "a girl" --restore_faces true
--prompt "steppe" --sampler_name "DPM++ SDE Karras" --seed 2740754650这会生成四张图片,分别是
城市
雪山
一个女孩,开启面部修复
草原,指定采样方法为:DPM++ SDE Karras ,随机种子是:2740754650
7.2.3 输入规则
参数格式:
–参数名称 “字符串”
eg:--prompt "a beautiful girl,pink hair,black glasses" --sampler_name "DPM++ SDE Karras"
–参数名称 数值/布尔值
eg:--steps 20 --seed 2740754650 --restore_faces true
字符串需要用半角引号括起来,而数值不需要用半角引号括起来,布尔值(ture/false)也不需要用半角引号括起来,参数与参数之间用半角空格隔开,eg 是例如的意思。
restore_faces 为面部修复,默认为 false,如需要开启面部修复,则参数中要设置为 true。
7.2.4 常用参数
提示词脚本支持更复杂的批处理任务,可以通过以下参数指定提示词的模型、采样器、采样步数、宽/高等参数。
sd_model:模型名称
outpath_samples:样本输出路径
outpath_grids:网格输出路径
prompt_for_display:用于展示的提示词
prompt:正向提示词
negative_prompt:反向提示词
styles:提示词模板(自定义的提示词模板)
seed:随机种子
subseed_strength:次级种子强度
subseed:次级种子
seed_resize_from_h:次级种子高度
seed_resize_from_w:次级种子宽度
sampler_index:采样器索引
sampler_name:采样器名称
batch_size:生成批次
n_iter:每批数量
steps:采样迭代步数
cfg_scale:提词相关性
width:宽度
height:高度
restore_faces:面部修复
tiling:平铺
do_not_save_samples:不保存样本
do_not_save_grid:不保存网格[h2]7.3 X/Y/Z 图表[/h2]

X/Y/Z 图表(X/Y/Z plot)是一个非常实用的功能,这个脚本可以快速帮助我们对不同参数进行测试和对比。
7.3.1 选项作用
X/Y/Z 轴的类型:
根据每个轴来确定要比较的要素,如下图所示,可以从下拉菜单中进行选择。

X/Y/Z 轴的值:
轴的类型不同,轴的值元素输入有不同的方法,下面列举常用的输入方法。
| 要素 | 输入值的类型 | 示例 |
| 随机种子(seed) | 整数(-1,0,1,2,3……) | |
每个轴的设定值。如后文所述,填写时需要遵循规定的格式
- 显示类型和值: 是否绘制表格标题
- 宫格图边框间距: 表格图像之间的间隔。如果设置为大于0的值,将会产生间隙
X/Y/Z 轴均可以对以上参数进行设置
[h1]9.图生图教程[/h1]